Services
Services
Automation
Cybersecurity
Cloud Ascension
Transformative Services
Digital Experience
Data Intelligence
Digital Compass
Second Edition: AI
Navigating the evolving AI landscape is equal parts exciting and arduous. From a step-by-step guide for implementation to legal considerations, our specialists share their diverse perspectives and insights into the world of AI.
Read more
Advisory
Advisory
Office of the CTO
Innovation Advisory
Digital Compass
Second Edition: AI
Navigating the evolving AI landscape is equal parts exciting and arduous. From a step-by-step guide for implementation to legal considerations, our specialists share their diverse perspectives and insights into the world of AI.
Read more
Resources
Insights
News
Digital Compass
Digital Compass
Second Edition: AI
Navigating the evolving AI landscape is equal parts exciting and arduous. From a step-by-step guide for implementation to legal considerations, our specialists share their diverse perspectives and insights into the world of AI.
Read more
About Us
About Us
Leadership Team
Culture
Digital Compass
Second Edition: AI
Navigating the evolving AI landscape is equal parts exciting and arduous. From a step-by-step guide for implementation to legal considerations, our specialists share their diverse perspectives and insights into the world of AI.
Read more
Join Our Team
Join Our Team
Contact Us
Contact Us
Related Articles
What the SEC Climate-Related Disclosure Ruling Really Means for Large Enterprises
Don’t Ignore Attack Surface during M&A
Embracing the Future of Offensive Security Balancing Automation with Expertise
Product Mindsets Create Business Value
Navigating Generative AI-Enabled Applications
Drive Digital Agility in Your Enterprise with Platform Engineering
Unwrapping Security for the Holidays: 4 Tips for Cybersecurity in Hospitality
Acquisition Cybersecurity: Leaving cybersecurity hanging will cause irritation later
Generative AI as a Boardroom Priority - Interview with Murali Nemani Part 1
Leading Applications of Generative AI - Interview with Murali Nemani Part 2
Building Versus Buying Generative AI - Interview with Murali Nemani Part 3
Actionable Advice to Get Started with Generative AI - Interview with Murali Nemani Part 4
The ‘Out of Control Cloud Cost' Buck Stops Here
Humans in the Software Development Loop
Enable High Speed Development Security with a Secure Toolchain
Unleash Unicorns to Lead the Charge in DevSecOps
“Hey ChatGPT, it’s not you, it's really us.”
Beyond Hyperautomation: The Value of Holistic Automation
Employee Digital Experiences Drive M&A Success
Accelerate Your Secure Toolchain Adoption
Your Attack Surface is not just a Buzzword
M&A Case Study: A Law Firm Learns the Value of OCM
Robotic Process Automation: The Razor Vs A Broom
Robotic Process Automation (RPA): Vendor Selection Demystified
The CMDB is Dead; Long Live the CMDB
Brain-Computer Interface: Technology of the Not-So-Distant Future
Low-code Development Platforms
Technical Manager's Guide to Zero Trust - Data
Technical Manager’s Guide- Devices Insights
DevSecOps Disruptors and Innovators
RPA Case Study: A Tale of Two Bots
Future of Cyberinsurance
The Metaverse: Securing the Future
Technical Manager’s Guide to Zero Trust: Identity
Artificial Intelligence for Healthcare Administration: A Powerful Tool for Alleviating Administrative Burdens
Anatomizing the Developer Shortage
Technical Manager’s Guide to Zero Trust: Applications
Zero Trust Vendors to Watch, Know, Understand: ZT Applications
Rethinking Citizen Developers
Technical Manager’s Guide to Zero Trust: Infrastructure
Zero Trust Vendors to Watch, Know, Understand: ZT Infrastructure
Clear the Fog with Application Dependency Mapping
Technical Manager’s Guide to Zero Trust: Network
Give Analyst Superpowers with a Citizen Data Science Program
Zero Trust Vendors to Watch, Know, Understand: ZT Network
An Executive Guide to Zero Trust
Beyond Automated Cloud Security
Zero Trust Metrics
The GreenOps Revolution
Activate Your Data with Operational Analytics and Reverse ETL
It’s the Year of RPA
The Path to Zero Trust
The Zero Trust Rollout Notebook
Maximize the Value of Digital M&A with Enterprise Architecture
Key Zero Trust Technologies and Management Imperatives
Zero Trust Business Objectives
How FinOps Has Enabled Startups to Compete with Public Cloud Giants
Take Control of Cloud Costs With FinOps
Zero Trust Interest and Investment Drivers
Zero Trust Sponsorship and Commitment
Defining Zero Trust
A Path Through the Wilderness
Validating Attack Surface Management Assumptions
Innovations pushing the boundaries of Cybersecurity
ACING Your Purchased Business Applications
Making every day “Earth Day”
Governance, Risk & Compliance (GRC): Vendors to Watch, Know, Understand
Demystifying the Enterprise Data Stack
Cybersecurity Strategy for the Looming Regulatory Quagmire
Workplace Experience Management
ASM/CV: Vendors to Watch, Know, Understand
Virtual Desktops, DaaS & the Future of Work
The FIUYMI Fallacy
Building an Effective Data Team
Automating Defense: Implementing Continuous Discovery & Validation
Stratascale Threat Advisory: Everything You Need to Know About the Critical Apache Log4j Remote Code Execution Vulnerability
Business Observability
Succeed with Industry 4.0 Transformation
SHI Expands AWS Relationship to Support AWS Control Tower
Decision Intelligence in a World of Endless Predictions
Moving Closer to Zero Trust with Stronger Identity and Access Management
Goodbye Monolithic System, Hello Quick & Effective Specialization with Microservices
Increasing Speed, Standardization, and Security with Containers
If You’re Serious About Performance, It’s Time to Talk About SASE
It’s Time to Evolve Your Protection with a Modern SOC
Gartner IT Symposium – Day 2 Doubles Down on the Tech-defined Future
Gartner IT Symposium – Day 1 Zeroes in on Digital Transformation
User Observability: Drive Competitive Advantage by Improving User Experience
Keeping Pace with the Ever-Changing Scope of Data Protection
Control Data Sprawl with Classification and Governance
6 Ways User Experience Should Lead Your Digital Transformation
Transforming with Edge Computing: the Retail Experience
Addressing Critical Infrastructure by Adopting a Cybersecurity Convergence Model
Stratacast Perspectives– Ransomware and Staying Ahead of Your Attackers
How to Win Over Your Board: Advice from a Seasoned CISO
Leave Passwords Behind: It’s FIDO Time
Optimize Your Decision Making with Graph Analytics
Cyber Risk Quantification: How to Align Security Risks to Business Objectives & Budgets
System Observability: Understanding Critical Business Systems to Improve Digital Agility
3 Steps to Secure Your Cloud While Getting Maximum Benefit
How to Reduce Your Technical Debt: Strategies for Finding and Replacing Systems That Slow Your Business Down
Stratagraphic: Common Mistakes That Can Ground Your Cloud Migration Journey
Stratascale Transformative Services: Business Vision Meets Tech Capability
Learn How to Win with IoT at the Edge
Driving Competitive Advantage with MLOps
High-Profile Tech Failures are Making People Scared and Angry—and They Should Be
Zero Trust Series: Access Management
The SOC Paradox: Do you Need More Headcount for Your Security Team?
Zero Trust: A 5-Point Plan to Modernizing Secure Access
Achieving Full Organizational Observability
How to Jump-Start Automation in Your Organization
Building the Right Cloud Strategy With Expert Guidance From the Field
How to Fund Innovation: Four Tactics to Increase Investment in Business-changing Ideas—Regardless of Your Budget
The Data-Centric Approach & How Improving Data Quality Enables Impactful AI
How to Combat Cybersecurity Tool Sprawl: 4 Steps to Bolster Your Security Posture
Zero Trust Series: Device Assurance
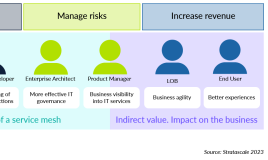
How Service Mesh Fits in Your IT Strategy
Cloud Cost Optimization
Treating Data as a Strategic Asset
Empowering the Hybrid Workforce: How To Optimize Your Employee Digital Experience Wherever They Work
The Text Conversation with My Cybersecurity Savvy Wife
Digital Risk Protection Has Crossed the Chasm
Leading with Strategy: Stratascale’s Office of the CTO/CISO Achieves Peer-to-Peer Guidance at the Highest Level
Zero Trust Series: Identity Management
Stratascale Adapts Cybersecurity for the New Normal
So You’re in the Cloud – What’s Next? Follow These Steps to Maximize Your Cloud Experience
Unlocking Hybrid Cloud’s Full Potential is the First Step to Enterprise-level Digital Agility
Why We Should Change the Conversation Around “AI”
The Crux of Convenience: IoT Risks to Enterprise Organizations
Stratascale’s Innovation Advisory is a Game Changer in the Field of IT and Consulting
So Your CFO Wants to Drive IT - What’s Next? Five ways technology leaders can create effective partnerships with their CFO
Stratascale’s Automation at Scale Solutions Use Digital Agility to Define Maximum Customer Value
So, You Survived a Ransomware Attack - What's Next? Practical advice for IT leaders
Why I Didn't Hate 2020 and What’s Next in 2021
Stratascale is Taking a Systems Integrator and Analyst Firm Approach to Business Consulting
Please enable JavaScript to continue using this application.